
Whether you’re opening your first notebook or refining a production pipeline, clear direction turns complexity into momentum. This article is your map and toolkit for doing just that: practical how‑to guides, step‑by‑step tutorials, and distilled best practices for building, shipping, and maintaining AI solutions-including how to deploy AI models reliably and at scale..
Expect concise checklists, reproducible steps, and decision points that make trade‑offs explicit. We’ll cover the path end to end: environment setup, data workflows, model training and evaluation, deployment patterns, CI/CD, monitoring, security and compliance, cost control, and troubleshooting. Each tutorial follows a consistent structure-what you’ll need, estimated time and difficulty, step sequence, validation tips, common pitfalls, and next steps-so you can move from prototype to production with confidence.
Whether you’re a newcomer seeking a clear starting point or an experienced practitioner looking for field‑tested patterns, use these guides as a reference you can return to, adapt, and apply. The goal is simple: fewer surprises, faster feedback, and solutions that stand up in the real world.
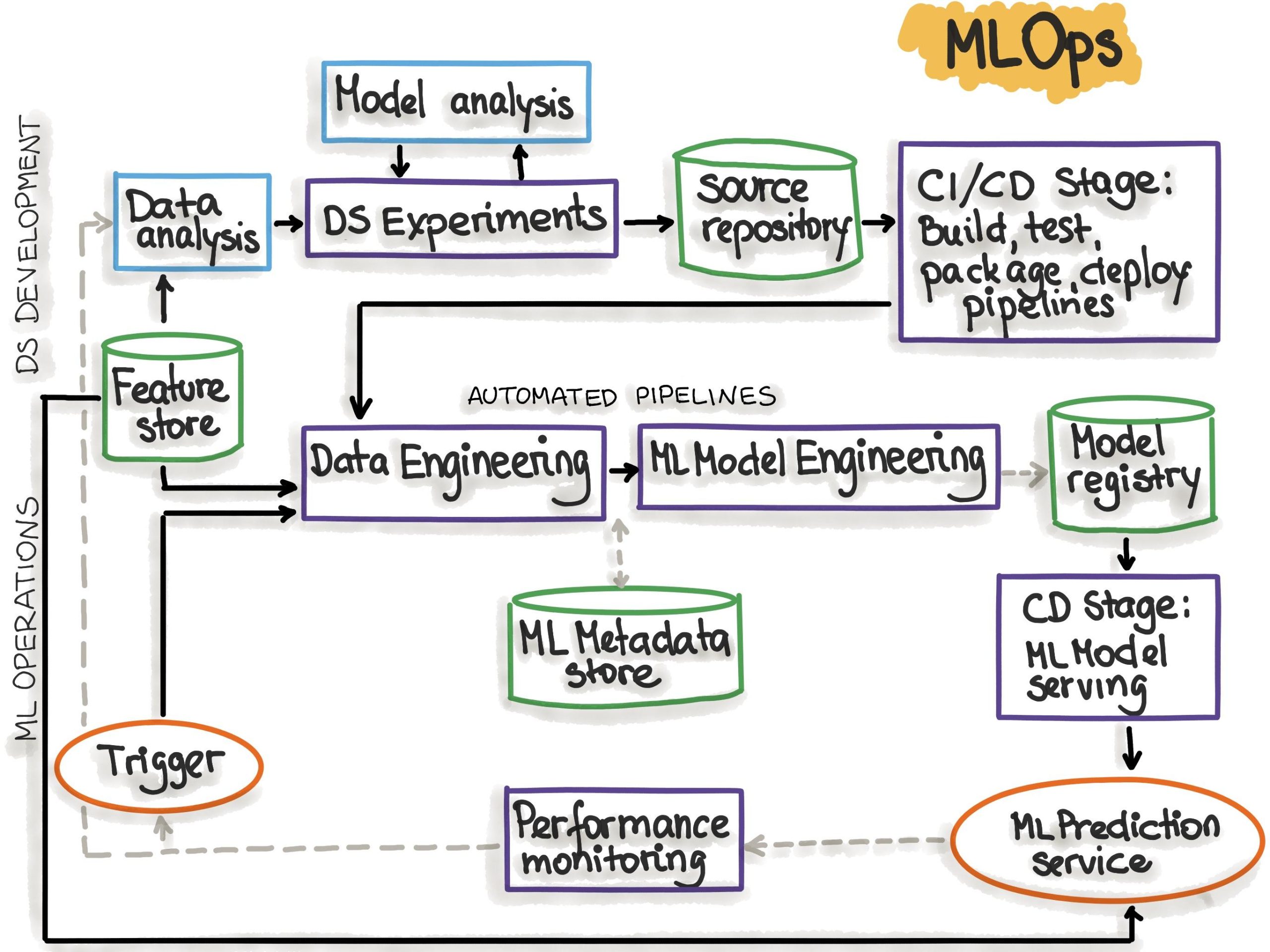
Step by step path from experiment to production with clear ownership and guardrails
Turn experiments into shippable systems by standardizing a narrow set of artifacts and handoffs: a concise problem brief, a reproducible experiment (seeded runs, pinned deps), a versioned dataset/feature spec, and a model card with risks and evals. Wrap notebooks into pipelines, enforce environment parity (dev/stage/prod), and promote via pull requests with automated checks. Use a model registry + feature store for traceability, and wire a lightweight CI/CD that runs unit tests, data/contract tests, and offline evals before any promotion. Every gate should have a named owner and a documented exit criterion so “good enough” is measurable, not debatable.
- Discovery owner: Product + Data Science (use-case, KPIs, success metrics)
- Experiment owner: Data Science (baseline, ablations, model card)
- Validation owner: ML Engineering (pipeline, tests, infra)
- Release owner: Platform/DevOps (deploy, rollback, SLOs)
- Risk owner: Security/Legal (privacy, compliance, usage policy)
| Stage | Artifact | Owner | Gate |
|---|---|---|---|
| Experiment | Model card + runs | DS | Repro + KPI delta |
| Staging | Pipeline + tests | MLE | CI green + evals |
| Production | Image + config | Platform | SLOs + rollback |
Build guardrails into the path, not after it: codify privacy and safety as automated checks (PII scans, policy-as-code), require evaluation harnesses with thresholds (quality, bias, robustness), and add red-teaming for prompt/attack resilience when applicable. Ship safely with canary or shadow traffic, budgeted rate limits, and kill switches; monitor latency, drift, cost-to-serve, and user feedback, then close the loop with scheduled re-evals and retrains. Document the runbook (alerts, on-call, rollback) so ownership persists beyond launch.
- Data: consent lineage, PII detection, retention windows
- Model: thresholded evals, fairness checks, jailbreak/prompt-injection tests
- Code/Infra: IaC, SBOM, secrets management, env parity
- Runtime: drift monitors, circuit breakers, human-in-the-loop, feedback capture
Infrastructure choices that meet latency throughput and budget constraints
Start with SLOs, not hardware: define target p95 response time (e.g., 120 ms), sustained tokens/sec and peak concurrency, plus a hard $/1k tokens ceiling. From there, map to topology. For sub‑50 ms interactions or offline privacy, go on‑device (quantized small models, WebGPU/Metal); for interactive UX in many regions, deploy edge GPUs/CPUs with micro‑batching; for heavy generation and RAG, use regional GPU pools with autoscaling. Keep prompts small (router + specialist models), enable KV‑cache reuse/prompt caching, and prefer speculative decoding or draft models to lift throughput without blowing up latency. Co‑locate vector stores with inference, pin requests to the nearest healthy region, and pick quantization (INT4/8) over brute‑force hardware when budgets are tight.
- Latency floor: < 10 ms → on‑device; 10-80 ms → edge; 80-250 ms → single‑region GPU; > 250 ms acceptable → multi‑region or cheaper instances.
- Throughput levers: dynamic batching (Triton/TensorRT), token streaming, CPU for embeddings, GPU for generation, shard by tenant to keep KV hot.
- Budget guardrails: spot/preemptible mixed with on‑demand, serverless for bursty traffic, max tokens and timeouts, tiered fallback (fast small model → bigger model on retry).
- Reliability: circuit breakers, regional failover, warm pools, and per‑tier QoS (VIP vs free) with different batch sizes.
| Option | p95 target | Throughput pattern | Cost profile | Best for |
|---|---|---|---|---|
| On‑device (INT4) | 5-30 ms | Low, local | Near‑zero | UX hints, privacy |
| Edge CPU/GPU | 20-80 ms | Spiky | $$ | Interactive chat, A/B |
| Regional GPU pool | 80-200 ms | High, steady | $$$ | Gen, RAG, tools |
| CPU + batching | 200-500 ms | Bulk | $ | Embeddings, ETL |
| Hybrid (cache + cloud) | Variable | Mixed | $$ | Cost‑aware scale |
Operationalize with autoscaling SLOs (scale on queue depth and tokens/sec), request shaping (max new tokens, temperature, top‑p), and model routers that pick between distilled, medium, and large variants based on prompt complexity. Track cost per successful completion, p95 latency, and throughput per GPU as first‑class dashboards; set budgets that trip fallbacks (e.g., switch to INT8, shrink context, or route to serverless). This lets you deploy step‑by‑step-from a single regional GPU with dynamic batching to multi‑region edge inference-while staying within latency and throughput goals without breaking the bank.

Packaging and serving models through containers APIs and workflow orchestration
Containerize the model by snapshotting all artifacts (weights, tokenizer, config) and pinning dependencies for bit-for-bit reproducibility. Choose a minimal, accelerator-aware base (e.g., CUDA or ROCm), and use multi-stage builds to compile and strip extras. Favor a model server (NVIDIA Triton, TorchServe, BentoML) when you need high concurrency and dynamic batching; otherwise, a lean FastAPI + Uvicorn or gRPC microservice can be faster to iterate. Bake in health checks, warmup routines, and a predictable /v1/predict contract; keep the image distroless, run as non-root, and expose structured logs and metrics (Prometheus, OpenTelemetry) by default. Optimize startup by preloading weights on container start, leveraging ONNX or TensorRT conversions, and externalizing large artifacts via read-only volumes or a registry-backed cache.
- Dockerfile essentials: multi-stage build, locked wheels, cache mounts, non-root user, healthcheck, read-only FS, and minimal shell footprint.
- Performance: dynamic batching, gRPC streaming, request timeouts, CPU/GPU affinity, threadpool tuning, and cold-start warmers.
- Security: image signing (Sigstore/Cosign), SBOM, vulnerability scans, mTLS, and least-privilege IAM for pulling models.
- Interfaces: REST for ubiquity, gRPC for low latency; ensure consistent schemas and version with
v1/v2paths.
| Layer | Option | Why |
|---|---|---|
| Model Server | Triton, TorchServe, BentoML | Batching, multi-model, metrics |
| API | FastAPI, gRPC | Fast, typed contracts |
| Orchestrator | Argo, Airflow, Prefect | DAGs, retries, lineage |
| Autoscale | KEDA, HPA, Knative | Cost-aware scaling |
| Registry | MLflow, SageMaker | Versioned artifacts |
Orchestrate the lifecycle with a build-and-release pipeline that fetches the latest approved model, runs canary validations (quality, latency, drift), compiles artifacts (ONNX/TensorRT), builds and signs the image, then promotes it through environments with progressive delivery (blue/green, canary via Istio/Linkerd). Use Argo/Airflow/Prefect to coordinate data pulls, feature checks, shadow traffic, and rollback gates. For online serving, pair event-driven autoscaling (KEDA) with pod-level budgets and surge controls; for batch inference, schedule GPU pools with quotas and backpressure. Capture inference telemetry (inputs hashed, predictions, timings) to a lakehouse for drift detection and retraining triggers, and enforce SLOs via alerts on P99 latency and error budgets. Keep secrets in Vault/KMS, rotate tokens, and verify releases with policy-as-code (OPA). When traffic spikes, enable request hedging and cache embeddings/results; when costs spike, downshift precision or route to CPU fallbacks while preserving correctness guarantees.
Best practices for monitoring drift reliability and cost with playbooks and rollbacks
Treat model health as a single control loop that balances data drift, reliability, and spend. Define concrete SLIs per segment (e.g., PSI/KL for features, p95 latency, error rate, human-rating or win-rate, and cost per 1k requests), then bind them to SLOs with burn-rate alerts and budget caps for tokens/GPU-minutes. Establish both rolling and anchored baselines, tag traffic by cohort (region, persona, device), and compare canaries against control. Log full provenance-model/prompt version, feature snapshot, infra SKU, unit price-so every anomaly is traceable and reproducible. Use streaming checks for fast guardrails and batch jobs for deeper drift diagnostics; prioritize alerts by user impact, not just metric volatility.
- Trigger: Clear thresholds and alert tiers (page on user-impacting, ticket on informational).
- Diagnose: Slice by cohort; inspect top-shifting features, null spikes, prompt diffs, and capacity events.
- Mitigate: Rate-limit, autoscale, or route to a cheaper/better model; enable cache or truncated context.
- Decide: Guardrail rules-as-code; pre-approved conditions for pause, roll-forward, or revert.
- Verify: Post-change smoke tests and shadow comparisons; watch p95/p99 and error budgets.
- Communicate: Status updates, incident notes, and follow-up actions linked to the change record.
| Signal | Threshold | Auto-action | Owner |
|---|---|---|---|
| Feature drift | PSI > 0.3 | Shadow + cache hot paths | Data |
| Latency | p95 > 300 ms | Scale out / reduce beam | SRE |
| Cost burn | > 2x hourly budget | Route to cheaper tier | FinOps |
| Quality | Win-rate ↓ 1 pt | Pause canary | ML |
- Feature-flag flip: Toggle prompts, truncation, or safety filters instantly with staged rollout.
- Registry pin: Revert to last good model/checkpoint with immutable artifacts and schema lock.
- Canary auto-halt: Stop at first error-budget breach; keep shadow collecting for root-cause.
- Blue/Green: Swap traffic atomically; keep warm standby to avoid cold-start penalties.
- Prompt rollback: Version prompts/templates; store eval deltas to recover expected tone/format.
- Fallback tree: Define cheaper/simpler routes (rules, retrieval-only, cache) when costs spike.
Operationalize enforcement with policy-as-code and change windows tied to error budgets. Precompute rollback artifacts (container image, prompt bundle, feature view), run chaos and drill simulations, and re-baseline after known distribution shifts. Apply progressive delivery (1%→5%→25% with quality and spend gates), rate-limit new cohorts, and freeze deploys during budget burn. Tag all resources for cost attribution and set per-feature cardinality guards to prevent metric blowups. Track outcomes-MTTR, change-failure rate, SLO attainment, and budget adherence-and fold them back into thresholds, routing policies, and playbook steps.
Closing Remarks
If the walkthroughs above are the map, your stack is the terrain. The path from prototype to production rarely runs in a straight line, but with clear steps, good habits, and a feedback loop, you can navigate it with fewer surprises.
Before you ship, pause for a final checklist:
– Reproducibility: pinned data, code, and model versions; deterministic builds.
– Quality gates: offline metrics tied to business outcomes; canary or shadow tests.
– Safety and governance: privacy reviews, bias checks, model cards, approval trails.
– Operations: observability for inputs, predictions, drift, and costs; clear SLOs.
– Resilience: rollbacks, circuit breakers, feature flags, and incident runbooks.
– Documentation: deployment diagrams, dependency lists, and onboarding notes.
From here, iterate in small slices. Start with a narrow use case, define exit criteria, measure impact, and adjust. Keep your “how-to”s living and local-adapt the best practices to your tooling, risk profile, and compliance environment, and retire steps that no longer serve you.
If a guide helped, bookmark it. If it didn’t, improve it. The strongest AI deployments are less about heroic launches and more about steady, visible learning. Close this tab, open your backlog, and move one change from “unknown” to “understood.” The rest will follow.